






















When developing locally I usually incorporate Docker Compose into my local development workflow: Bringing up supporting containers needed to run databases, reverse proxies, other applications, or just to see how the container I'm developing works. Given that Docker Desktop comes with a single node Kubernetes (K8s) cluster and I usually end up deploying my containers to a Kubernetes cluster, I wanted to figure out if I can switch from Docker-Compose to Kubernetes for local development. It's also a good way to work the kinks out of Kubernetes manifests or Helm charts without disrupting any shared environments.
There are five things I need to be able to do in order to replace Docker-Compose with Kubernetes:
- Build an image locally and run it on the Kubernetes.
- Make changes to an app and redeploy on Kubernetes.
- Make an easily accessible volume mount on a container in Kubernetes.
- Have Kubernetes apps easily communicate with host OS apps.
- Have host OS apps easily communicate with Kubernetes apps.
If you want to skip to how all of this works out here's the TL;DR otherwise keep reading.
Warning: The rest of this post assumes some familiarity with Docker and Kubernetes.
You can find sample applications that demonstrate all of this in this monorepo along with an explanation to get up and running.
Build an image locally and run it on the Kubernetes
With Docker Compose I can build an image and run it with just one simple command docker-compose up --build, assuming I have my docker-compose files setup. What's the analogue of this with Kubernetes? When I build an image, how can Kubernetes pull it? Do I need a local Docker Registry to push my image to?
The answer to that last question, luckily, is "No". When building an image locally using the standard docker build command docker build --tag my-image:local . the image is stored in docker's image cache. This is the same image cache Kubernetes will use because it's using the same docker instance. There are two things to note here:
- The image name of a Kubernetes pod must exactly match the name given via the --tag parameter of the docker build command. In the example given it's my-image:local
- The imagePullPolicy must be set to Never or IfNotPresent. It cannot be set to Always otherwise Kubernetes will attempt to pull the image from a remote registry like Docker Hub, and it would fail.

That covers how to build and run an image locally.

Make Changes to an app and redeploy on Kubernetes
If I were making changes to the application or its image definition (ie, Dockerfile) and wanted to see it running in Docker Compose I would just run the command docker-compose up --build. For Kubernetes we can rebuild the image docker build --tag my-image:local. That much is the same as the initial build, but you will probably notice your changes aren't actually running in Kubernetes right away.
The problem is there's been no signal for Kubernetes to do anything after the image was built. The solution is to delete the pod the image was running in and recreate it. If you are running a single unmanaged pod (which I think is unlikely) you would have to delete it and recreate it yourself from the pod definition yaml. If you're running a deployment or a statefulset you can either delete the pods and they will automatically be recreated for you, or you can scale down the replicas to 0 and then back up again:
- Delete a pod: kubectl delete pod my-pod-xyz --force
- Scale down kubectl scale deployment my-deployment --replicas=0 and then back up kubectl scale deployment my-deployment --replicas=3
Make an easily accessible volume mount on a container in Kubernetes
In Docker Compose, volumes can be straightforward in that we can mount any file or subdirectory relative to the directory we are executing docker-compose from. That makes it easy to find, inspect and clean up those files. But Kubernetes is not the same. It's not running from a project's folder like Docker Compose, it's already running on the Docker Desktop Virtual Machine somewhere. So, if we defined a volume to mount into a container, where would the data for that volume live? It lives in the Docker Desktop Virtual Machine somewhere (unless we're running WSL 2). Luckily, Docker Desktop has file sharing setup with the host OS so we can take advantage of this to do any inspection or cleanup of persistent data.
Going into the Docker Desktop dashboard under Settings/Preferences -> Resources -> File Sharing I can see and manage all of the file sharing that is available. Using this information, I can create a hostPath Persistent Volume that my application can claim and use. In my example below I picked a path under /Users since that was already shared (on MacOS):

This volume obviously differs from what you would use in your dev or prod Kubernetes clusters, so I recommend having a folder of "local" persistent volume definition yamls like this that can be reused by team mates (or your future self) to populate their Kubernetes with. Unfortunately you may have no choice but to have different persistent volume yamls for both Mac and Windows if your team uses a mix of those.
One last thing - if you ever delete the claim to this Persistent Volume, you must delete and recreate the Persistent Volume too, if you ever want to run your application again in the future. This is not unique to local Kubernetes development.
Have Kubernetes apps easily communicate with host OS apps
Often, I will be working on an application in the host OS. Most of my primary development is done here, as you get the advantages of automatic rebuilds and IDE tooling, etc. There will be other applications that I'd like to run in Kubernetes that can talk to this application on the host OS. For example, I may have a reverse proxy like nginx running in Kubernetes that needs to serve up my host OS application. This is super easy and done exactly the same as we would do it with just Docker or Docker Compose: with the host.docker.internal DNS name.
An example of my nginx config running on Kubernetes that reverse proxies my app running on the host port 4200:
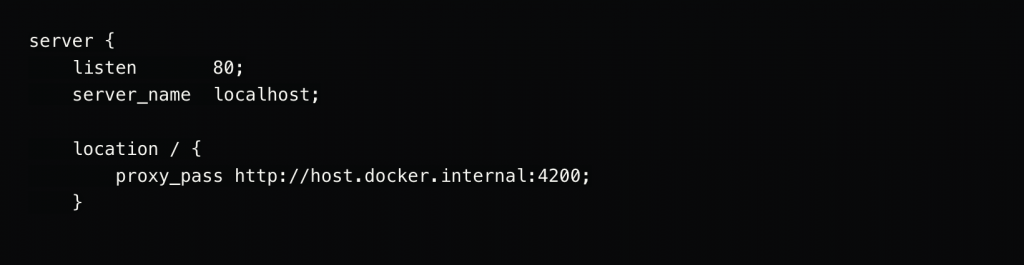
Have host OS apps easily communicate with Kubernetes apps
Whether I'm developing an application on the host OS that communicates with an application on Kubernetes, or if I want to access the application on Kubernetes in a web browser, or some kind of client, the application needs to be exposed. There are two ways to do this. The first, and not my recommended approach, is to use kubectl port-forwarding. I don't like this approach because you need to be re-run this command whenever you restart your cluster for every service that needs to be exposed. My preferred approach is to use a NodePort service.
A NodePort exposes a port on the Kubernetes node that you can access your application through and in Docker Desktop that exposes the port on your host OS.
So, I can create a service for my application like this:

And I can access my application at localhost:30001!
I prefer to define my nodePort for predictability of the port, but you can leave it empty for Kubernetes to decide what it should be. Then there's less chance of a collision for an already occupied port.
Chances are the application's service might be a ClusterIP or LoadBalancer type when deployed to other Kubernetes clusters, or that the nodePort will have a different value in those clusters. You can get around this by templating your service definition in Helm, and having different service configurations for your local Kubernetes versus other Kubernetes clusters.

Helm
Without Helm, or similar tools, using a local Kubernetes cluster for development is pointless beyond just experimentation purposes. We want to use the local Kubernetes cluster so that our running applications will mirror shared environments, like production as closely as possible. Helm lets us accomplish this by allowing us to template out our Kubernetes manifests, and abstract out only the necessary environmental differences into values files.
When you're using Helm you'll be creating values files for every environment. I recommend creating values files for local clusters as well that can be shared with the team. You can even create personal "overrides" values files that you can use to change some minor configurations for your own purposes (just be sure to .gitignore them). Helm lets you chain these files together, and gives precendence to the rightmost file. E.g., helm upgrade my-app ./my-app -f values-local.yaml -f .values-override.yaml.
Another benefit of Helm is in its package management. If your application requires another team's application up and running, they can publish their Helm chart to a remote repository like a ChartMuseum. You can then install their application into your Kubernetes by naming that remote chart combined with a local values file. E.g., helm install other-teams-app https://charts.mycompany.com/other-teams-app-1.2.3.tgz -f values-other-teams-app.yaml. This is convenient because it means you don't have to check out their project and dig through it for their helm charts to get up and running - all you need to supply is your own values file.
Scripting
Working with Kubernetes, and then layering in extra tools like Helm, there are a lot of commands to get to know. Most of your team will probably need some kind of containerized apps running locally, but it can be a high bar to expect them to know all of the docker and kubectl and helm commands. You will also want to take the things that are done often and condense them into some simpler scripts for your own convenience. Things like:
- Build and Install your app on the Kubernetes cluster:

- Build and restart your app:

- Update your configuration:

- Install another team or organization's app:

- Clean up
You can script this however you like, whether it be in bash, Makefile, npm scripts, Gradle tasks. Use whatever suits your team best.
Comparing to Docker Compose
Using Docker Compose for local development is undoubtedly more convenient than Kubernetes. For the most part you only need to be familiar with two commands to build, run, re-build and re-run, and shutdown your applications in docker: docker-compose up --build, and docker-compose down. For volumes, Docker Compose lets you mount a directory relative to where you execute docker-compose from and in a way that works across platforms. Docker Compose is also safer - there's no chance you're going to accidentally docker-compose up a mid-developed image into production!
Docker Compose has the disadvantage that it's a duplication of effort to recreate an analogue of your Kubernetes manifests into docker-compose files. Considering the extra configurations, volume definitions, and scripting that needs to be added for local Kubernetes development, this is probably a negligible difference.
Kubernetes, on the other hand, more accurately represents what you will be deploying into shared Kubernetes clusters or production. Using a tool like Helm gives us package manager-like features of installing externally developed manifest or dependencies without having to redefine them in your local repository.
Using Kubernetes requires a good familiarity with Kubernetes and its surrounding tools, or extra scripting to hide these details. These tools like kubectl and helm rely on a context which could be set to the wrong Kubernetes cluster, which would cause unwanted trouble! I recommend putting safeguards in place like setting up RBAC where possible in the shared or production Kubernetes clusters where possible. Or work within a namespace locally that does not exist in other clusters.

Final Thoughts
It's possible to replace Docker Compose with Kubernetes for local development, but for the added complexity and trade-offs it may be worth using both. For most local development, Docker Compose is probably good enough, and much simpler. Using a local Kubernetes cluster is a step up in terms of complexity and effort so it is up to you if you want to take that on. It is definitely worth it for Helm Chart / Manifest development or situations where you absolutely must re-create a part of your deployment architecture.
TL;DR
Building and running an image on Kubernetes works because Kubernetes will pull from the same shared image cache you built from, just make sure your pull policy is not 'Always'.
To re-build an image and re-run, just delete the old pods running the old image. Newly created pods will come up with the new image.
Docker Deskop's file sharing locations can be found and configured in the Preferences/Settings. A Persistent Volume can be created with a hostPath to one of those locations.
Applications running on Kubernetes can access applications on the host OS via the host.docker.internal DNS name.
Applications running on Kubernetes can be accessed by setting up kubectl port forwarding and then accessed using localhost:{forwardedPort}. Or, even better, make the Application's service a nodePort service and access using localhost:{nodePort}.
Use Helm. Simplify the common tasks via scripting. Maybe don't ditch Docker Compose completely.





